

Photo by Guillaume de Germain on Unsplash
Spark Connect - Streamline Apache Spark Data Pipeline Development in Dagster
The new (and better) way to develop Apache Spark data pipelines


Table of contents
Introduction
In many years, the conventional way to develop data pipelines in Dagster with Apache Spark is submitting applications, which pose unique challenges to developers:
Require a separate infrastructure (cluster of machines with a cluster manager: Databricks, AWS EMR, Hadoop YARN, Standalone or Kubernetes) specialized for running Apache Spark applications.
Require submitting code to Spark cluster by uploading or pointing to Python/Java/Scala files that contain the actual Spark data transformations and actions. Therefore debugging is cumbersome, you have to go into Spark cluster's execution logs to check even basic information like DataFrame schema, number of columns or Spark execution plan. It just not a developer-friendly experience.

But since Apache Spark version 3.4, a new project called Spark Connect has introduces a decoupled client-server architecture for Apache Spark that allows remote connectivity to Spark clusters using the DataFrame API and unresolved logical plans as the protocol. Basically, we can run and interact with Spark Applications remotely from anywhere.
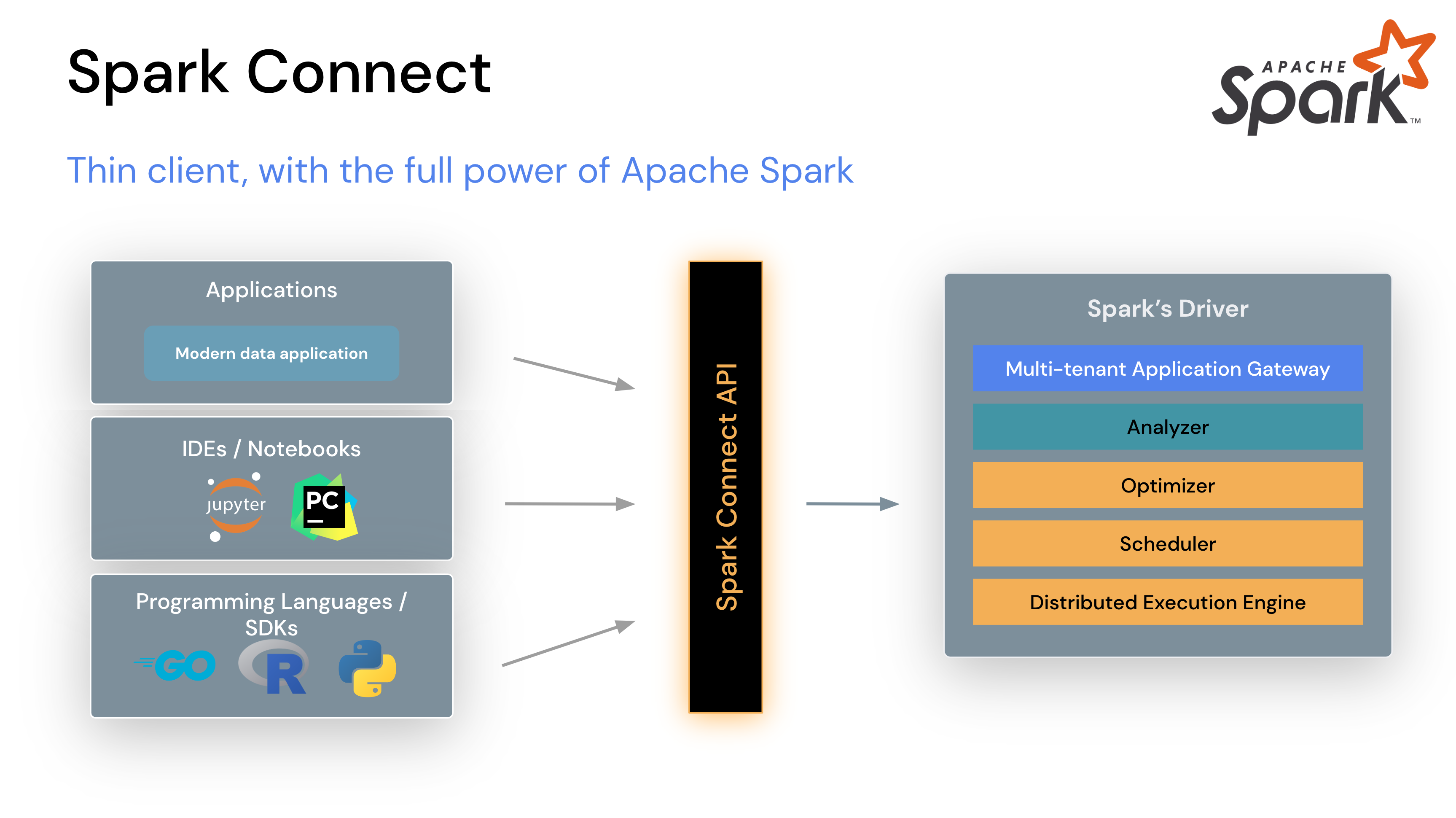
By utilizing Spark Connect API, we have a new approach of developing Spark data pipeline in Dagster which is more elegant and developer friendly. This new approach replace the spark submit method (fire and forget) by using a lightweight PySpark client to connect to Spark Connect server over gPRC (interactive), therefore we can get additional information about what is happening to the Spark job at runtime by calling Spark actions.

This approach allow developers to have a better local dev and test experience with a single Spark container as a Spark cluster, yet still be very confident when deploy to production because Spark Connect protocol is stable and consistent between environments (independent to the types of Spark cluster manager). The burden of managing Spark application's dependencies can also be transition to Spark Connect Server, so the developers can focus more on the transformation logic.
Implementation
To implement this approach to Dagster, we need to implement a custom Dagster Resource, inspired by PySparkConnectResource developed by Dagster team, to create a Spark Connect session for connecting to Spark Connect Server:
# function to create Spark Connect session
def spark_session_from_config(spark_remote, spark_conf=None):
spark_conf = check.opt_dict_param(spark_conf, "spark_conf")
builder = SparkSession.builder
flat = flatten_dict(spark_conf)
for key, value in flat:
builder = builder.config(key, value)
return builder.remote(spark_remote).getOrCreate()
# Spark Connect Resource with additional `spark_remote` attribute to point
# to Spark Connect Server in a URL formatted "sc://{host}:{port}"
class PySparkConnectResource(ConfigurableResource):
spark_remote: str
spark_config: Dict[str, Any]
_spark_session = PrivateAttr(default=None)
@classmethod
def _is_dagster_maintained(cls) -> bool:
return True
def setup_for_execution(self, context: InitResourceContext) -> None:
# get Spark Connect Session
self._spark_session = spark_session_from_config(
self.spark_remote, self.spark_config
)
@property
def spark_session(self) -> Any:
return self._spark_session
@property
def spark_context(self) -> Any:
return self.spark_session.sparkContext
Then we create a custom IOManager which read/write data using this new resource class:
# remember to use DataFrame class from Spark Connect
# not the usual DataFrame class
from pyspark.sql.connect.dataframe import DataFrame
class ParquetIOManager(ConfigurableIOManager):
pyspark: PySparkConnectResource # Spark Connect Resource
path_prefix: str
def _get_path(self, context) -> str:
return "/".join(
[context.resource_config["path_prefix"], *context.asset_key.path]
)
def handle_output(self, context, obj: DataFrame):
obj.write.parquet(self._get_path(context), mode="overwrite")
def load_input(self, context):
# use Spark Connect session from PySparkConnectResource
spark = self.pyspark.spark_session
return spark.read.parquet(self._get_path(context.upstream_output))
Then use these newly created classes to declare resources:
# create new resource instance
pyspark_resource = PySparkConnectResource(
spark_remote="sc://localhost", spark_config={}
)
# definitions to be load by Dagster
defs = Definitions(
assets=all_assets,
resources={
"pyspark": pyspark_resource,
"io_manager": ParquetIOManager(
pyspark=pyspark_resource, path_prefix="/opt/spark/work-dir"
),
},
)
The Spark Connect Server (with default port is 15002) can be started by executing following command:
./sbin/start-connect-server.sh --packages org.apache.spark:spark-connect_2.12:3.5.1
For detail about my simple implementation, please checkout my Github project at: https://github.com/Giangblackk/dagster-spark-connect.
The end
This is a short experimental article about utilizing Spark Connect to develop Spark-based data pipelines with Dagster. With the announcement of new release Apache Spark 4.0 in which Spark Connect will become general available, I hope to see more projects adopt this method to develop Spark applications, because I think it is the better way.
Thanks for reading, I love see your feedback ❤️